1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| import requests
session = requests.Session()
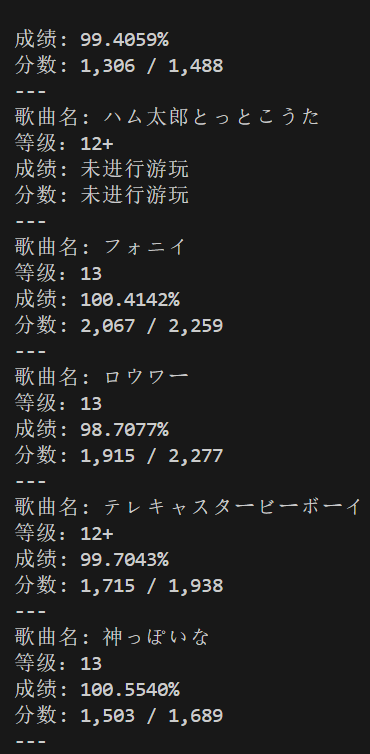
url1 = 'https://maimai.wahlap.com/maimai-mobile/record/musicGenre/search/?genre=99&diff=0'
url2 = 'https://maimai.wahlap.com/maimai-mobile/record/musicGenre/search/?genre=99&diff=1'
url3 = 'https://maimai.wahlap.com/maimai-mobile/record/musicGenre/search/?genre=99&diff=2'
url4 = 'https://maimai.wahlap.com/maimai-mobile/record/musicGenre/search/?genre=99&diff=3'
url5 = 'https://maimai.wahlap.com/maimai-mobile/record/musicGenre/search/?genre=99&diff=4'
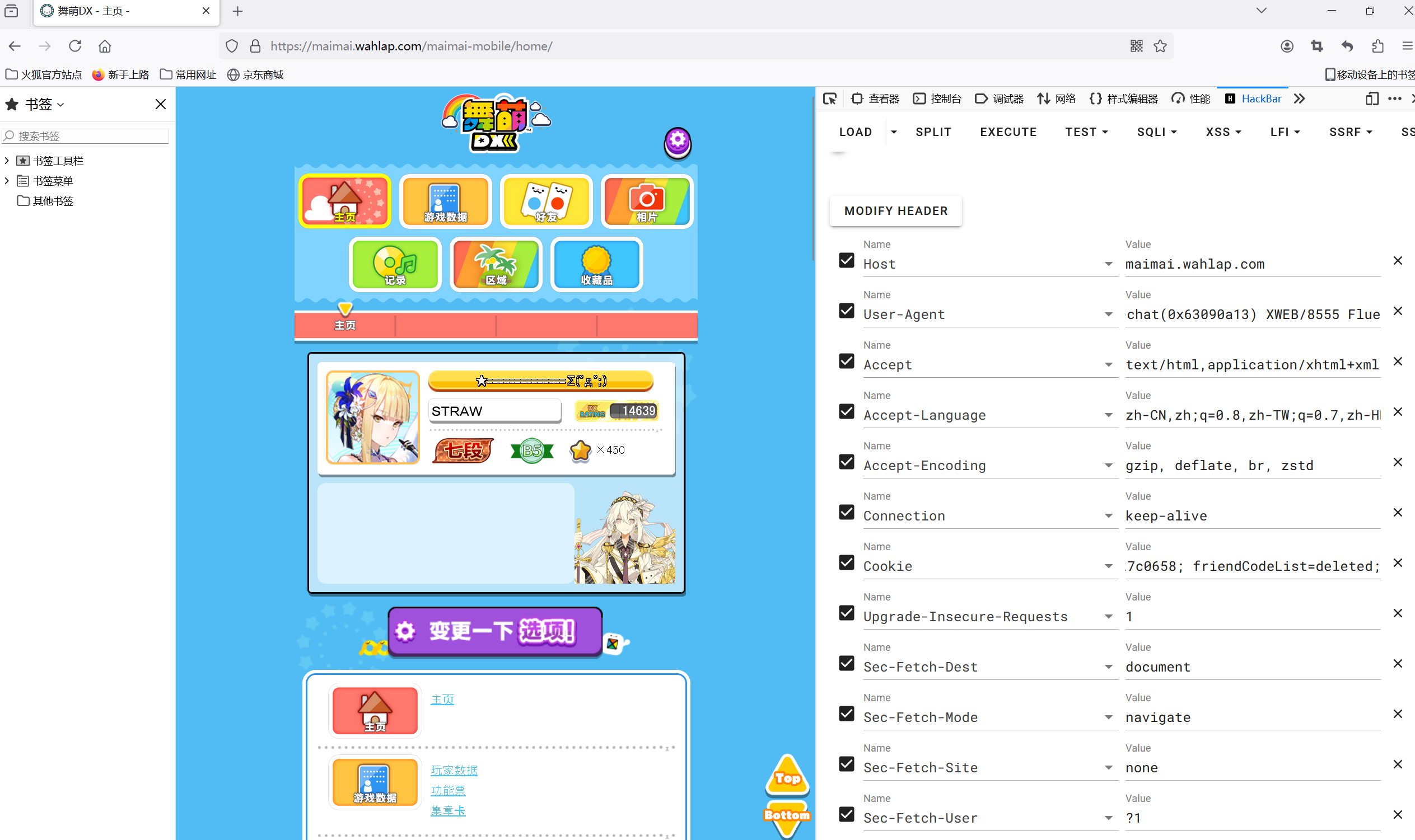
headers = {
'Host': 'maimai.wahlap.com',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090b11) XWEB/8555 Flue',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
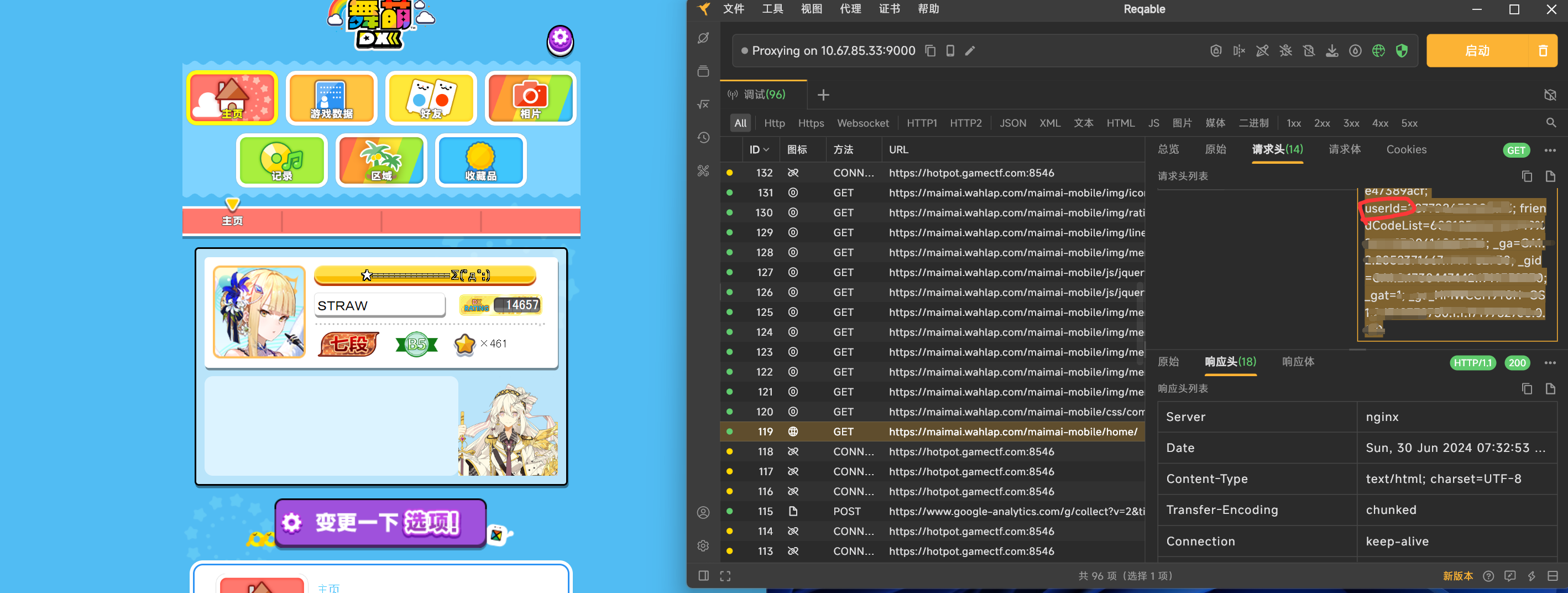
'Cookie': '_t=053aec723085f36dd132b8af227c0658; userId=2352886346959880;'
}
response_basic = session.get(url=url1, headers=headers)
response_advance = session.get(url=url2, headers=headers)
response_expert = session.get(url=url3, headers=headers)
response_master = session.get(url=url4, headers=headers)
response_rema = session.get(url=url5, headers=headers)
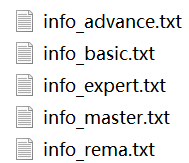
if "登录失败,请重试。" not in response_basic.text:
with open('info_basic.txt', 'w', encoding='utf-8') as file:
file.write(response_basic.text)
print("basic表已保存")
else:
print("登录失败,请重试。未写入basic表。")
if "登录失败,请重试。" not in response_advance.text:
with open('info_advance.txt', 'w', encoding='utf-8') as file:
file.write(response_advance.text)
print("advance表已保存")
else:
print("登录失败,请重试。未写入advance表。")
if "登录失败,请重试。" not in response_expert.text:
with open('info_expert.txt', 'w', encoding='utf-8') as file:
file.write(response_expert.text)
print("expert表已保存")
else:
print("登录失败,请重试。未写入expert表。")
if "登录失败,请重试。" not in response_master.text:
with open('info_master.txt', 'w', encoding='utf-8') as file:
file.write(response_master.text)
print("master表已保存")
else:
print("登录失败,请重试。未写入master表。")
if "登录失败,请重试。" not in response_rema.text:
with open('info_rema.txt', 'w', encoding='utf-8') as file:
file.write(response_rema.text)
print("rema表已保存")
else:
print("登录失败,请重试。未写入rema表。")
|